






En probabilité et en statistique, afin d’analyser des lois de probabilité des notions comme l’espérance, la variance ou encore les moments d’une variable aléatoire ont été développées. Dans cette perspective, la notion de kurtosis permet d’étudier le coefficient d’acuité (c’est-à-dire d’aplatissement) des distributions des variables aléatoires. Si cette notion est hors programme, elle pourrait toutefois être développée dans un sujet de type Maths II, et c’est pourquoi il peut être bon de s’y familiariser. Dans cet article, nous définirons la notion de kurtosis, avant de l’appliquer à quelques lois de probabilité classiques du programme. Enfin, nous étudierons les propriétés du kurtosis.
Définition
Le kurtosis d’une variable aléatoire \( X \) est défini comme le moment centré réduit d’ordre 4. Mathématiquement, pour une variable aléatoire \( X \) avec une moyenne \( \mu \) et un écart-type \( \sigma \), le kurtosis \( \kappa \) est donné par :
\begin{equation}
\kappa = \mathbb{E}\left[\left(\frac{X – \mu}{\sigma}\right)^4\right]
\end{equation}
En pratique, on utilise souvent l’excès de kurtosis, défini comme \( \kappa – 3 \), pour comparer le kurtosis d’une distribution à celui de la distribution normale (nous verrons dans la partie II de l’article d’où vient ce fameux \(-3\)).
Application du kurtosis aux lois classiques
Loi normale \( \mathcal{N}(\mu, \sigma^2) \)
Pour une variable aléatoire \( X \) suivant une loi normale, le kurtosis est de 3.
Note : il est possible de démontrer ce résultat de manière assez simple, mais cela prend pas mal de temps, car les calculs sont longs. Comme la variable \(Y=\frac{X-0}{1}\) suit encore une loi normale centrée réduite, on doit désormais calculer son moment d’ordre 4.
Ainsi, l’excès de kurtosis est bien défini comme :
\begin{equation}
\kappa – 3 = 0
\end{equation}
Cela signifie que la loi normale sert de référence pour mesurer l’excès de kurtosis d’autres distributions.
Loi uniforme \( \mathcal{U}(a, b) \)
Ici, tu peux aisément calculer les moments d’une loi uniforme à densité.
Pour une variable aléatoire \( X \) suivant une loi uniforme sur l’intervalle \([a, b]\), le kurtosis est donné par :
\begin{equation}
\kappa = \frac{9}{5} = 1.8
\end{equation}
Pour simplifier les calculs, je te propose de simplement déterminer le kurtosis d’une loi uniforme sur l’intervalle \([0;1]\).
\[
\mu = \mathbb{E}(X) = \frac{0 + 1}{2} = \frac{1}{2}
\]
\[
\sigma^2 = \mathbb{V}(X) = \frac{(1 – 0)^2}{12} = \frac{1}{12}
\quad \Rightarrow \quad \sigma^4 = \left( \frac{1}{12} \right)^2 = \frac{1}{144}
\]
On calcule :
\[
\mathbb{E}\left[(X – \mu)^4\right] = \mathbb{E}\left[\left(X – \frac{1}{2}\right)^4\right] = \int_0^1 \left(x – \frac{1}{2}\right)^4 dx
\]
Par changement de variable,
\[
\int_0^1 \left(x – \frac{1}{2}\right)^4 dx = \int_{-1/2}^{1/2} u^4 \, du
= \left[ \frac{u^5}{5} \right]_{-1/2}^{1/2}
= \frac{(1/2)^5 – (-1/2)^5}{5}
= \frac{2 \cdot (1/2)^5}{5}
= \frac{2}{5} \cdot \frac{1}{32}
= \frac{1}{80}
\]
Donc : \(\kappa = \frac{\frac{1}{80}}{\left( \frac{1}{12} \right)^2} = \frac{9}{5}\)
Loi de Student \( \mathcal{T}(\nu) \)
Pour une variable aléatoire \( X \) suivant une loi de Student avec \( \nu \) degrés de liberté, le kurtosis est donné par :
\begin{equation}
\kappa = 3 + \frac{6}{\nu – 4} \quad \text{pour} \quad \nu > 4
\end{equation}
Pour \( \nu \leq 4 \), le kurtosis n’est pas défini, car les moments d’ordre 4 ne sont pas finis.
Ce résultat nous sera utile pour la partie III qui visera à interpréter le kurtosis d’une variable aléatoire.
Interprétation du kurtosis
Voici un graphique des densités de quelques lois de référence au programme, à l’exception de la loi de Student, mais tombant tout de même de façon répétée dans les sujets de concours. L’analyse des densités permet de manière visuelle d’intuiter et de comparer des kurtosis de ces différentes lois de probabilité.
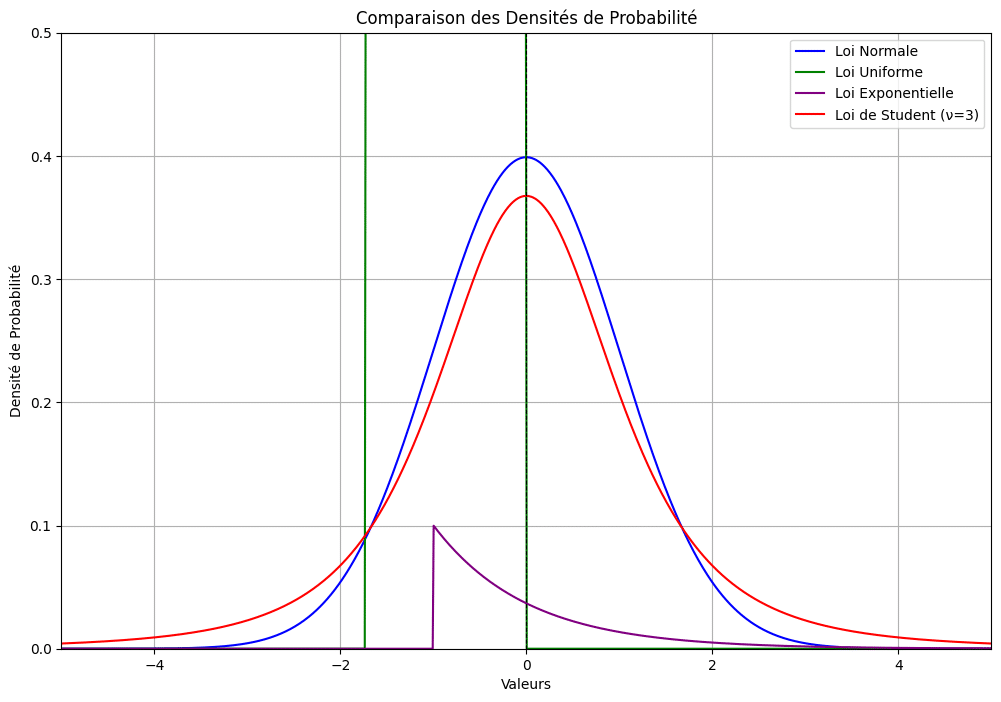
Pour indication, le kurtosis d’une loi exponentielle vaut 6 et celui d’une variable aléatoire suivant une loi de Student de paramètre \(a\) est, comme affirmé précédemment, de \(\frac{6}{a-4} + 3\) pour \(a>4\).
Ainsi, on remarque que le kurtosis d’une loi de Student est toujours supérieur à celui d’une loi normale, ce qui signifie que le coefficient d’aplatissement d’une densité de probabilité suivant une loi de Student est plus faible que celui d’une loi normale (voir graphique). Encore plus visible, le kurtosis de la loi exponentielle est effectivement (cela se vérifie graphiquement) supérieur à celui de la loi normale.
Propriétés
Notion d’excès de kurtosis
Comme nous l’avons déjà vu, une loi normale aura toujours un kurtosis de \(3\). Pour faciliter les comparaisons des kurtosis entre les différentes lois de probabilité, on définit régulièrement la notion d’excès de kurtosis qui désigne le réel suivant :
\[\kappa ‘ = \kappa – 3 \]
De sorte que l’excès de kurtosis d’une loi normale est nul et que l’excès de kurtosis permet de comparer aisément d’autres distributions à la normale.
Prenons un exemple : nous avons vu que le kurtosis d’une loi uniforme à densité est de \(1.8\), donc son excès de kurtosis est de \(-1.2\). Ainsi, la loi uniforme à densité a un coefficient d’aplatissement plus faible que la loi normale (cela se vérifie très aisément avec le graphique des densités de probabilité).
Invariance par transformation linéaire
Soit \(X\) une variable aléatoire admettant un moment centré d’ordre 4 fini, c’est-à-dire que \(\mathbb{E}[(X – \mu)^4]\) existe , où \(\mu = \mathbb{E}(X)\). On définit le kurtosis de \(X\) par :
\[
\kappa(X) = \frac{\mathbb{E}[(X – \mu)^4]}{\sigma^4}
\quad \text{où } \sigma^2 = \mathbb{V}(X)
\]
Soit maintenant une transformation affine :
\[
Y = aX + b, \quad \text{avec } a \neq 0
\]
On montre que le kurtosis est invariant sous une telle transformation, c’est-à-dire :
\[
\kappa(Y) = \kappa(X)
\]
Posons :
\[
\mu_Y = \mathbb{E}(Y) = \mathbb{E}(aX + b) = a \mu + b
\]
\[
\sigma_Y^2 = \mathbb{V}(Y) = \mathbb{V}(aX + b) = a^2 \sigma^2
\]
Donc :
\[
\kappa(Y) = \frac{\mathbb{E}[(Y – \mu_Y)^4]}{\sigma_Y^4}
= \frac{a^4 \mathbb{E}[(X – \mu)^4]}{a^4 \sigma^4}
= \frac{\mathbb{E}[(X – \mu)^4]}{\sigma^4}
= \kappa(X)
\]
Ainsi, on a bien vérifié que le kurtosis est invariant par toute transformation affine \( Y = aX + b \) avec \( a \neq 0 \).
Additivité pour les variables indépendantes
Pour des variables aléatoires indépendantes \( X_1, X_2, \ldots, X_n \) avec un kurtosis fini, le kurtosis de leur somme \( S = X_1 + X_2 + \ldots + X_n \) est donné par :
\begin{equation}
\kappa_S = \frac{\sum_{i=1}^n \sigma_i^4 \kappa_{X_i}}{\left(\sum_{i=1}^n \sigma_i^2\right)^2}
\end{equation}
où \( \sigma_i^2 \) est la variance de \( X_i \) et \( \kappa_{X_i} \) est le kurtosis de \( X_i \).
Il n’est pas utile de retenir une telle formule, mais plutôt de comprendre que l’on peut obtenir le kurtosis d’une somme de VAR sans qu’il soit pourtant égal à la somme des kurtosis (il n’y a pas de linéarité du kurtosis pour une somme de variables aléatoires indépendantes).
Conclusion
En définitive, le kurtosis est une nouvelle notion qui permet de décrire de manière d’autant plus précise que possible le comportement des densités de probabilité des variables aléatoires en se fondant sur le moment d’ordre 4 de la variable centrée réduite.
Comme la notion de kurtosis n’est jamais encore tombée telle quelle aux écrits, si tu veux t’entraîner sur une notion proche, tu peux aborder le sujet 2019 HEC/ESSEC voie ECE (maths appliquées), la partie IV tout particulièrement.



