






L’approximation de fonctions est un pilier des épreuves de mathématiques et d’informatique en ECG. Contrairement à l’interpolation de Lagrange, qui cherche à passer par des points, la projection orthogonale cherche à être la plus proche en moyenne, évitant ainsi les instabilités numériques, comme le phénomène de Runge (qui a d’ailleurs fait l’objet d’un sujet d’écrit Maths I il y a quelques années). Dans cet article, nous reviendrons rapidement sur le fondement théorique des polynômes orthogonaux, avant de présenter les modules Python par famille de fonctions et d’analyser l’implémentation en Python de cette méthode d’approximation.
Fondements théoriques : la projection orthogonale
En ECG, on travaille dans l’espace \(E = \mathcal{C}^0(I, \mathbb{R})\). On définit un produit scalaire lié à une fonction de poids \(w(t)\), souvent associée à une densité de probabilité classique :
\[ \langle f, g \rangle = \int_{I} f(t)g(t)w(t) dt \]
L’objectif est de trouver le polynôme \(P_n \in \mathbb{R}_n[X]\) qui minimise la distance quadratique à \(f\) :
\[ \min_{P \in \mathbb{R}_n[X]} \| f – P \|^2 = \min_{P \in \mathbb{R}_n[X]} \int_{I} (f(t) – P(t))^2 w(t) dt \]
Ici, \(w(t)\) est une fonction qui dépend de la famille polynomiale que nous allons utiliser. Pour simplifier, tu trouveras dans la deuxième partie de cet article le détail de cette fonction selon la famille polynomiale utilisée.
D’après le théorème de projection orthogonale, si \((Q_0, \dots, Q_n)\) est une famille de polynômes orthogonaux pour ce produit scalaire, alors l’approximation optimale est donnée par :
\[ P_n(t) = \sum_{k=0}^{n} \alpha_k Q_k(t) \quad \text{avec} \quad \alpha_k = \frac{\langle f, Q_k \rangle}{\| Q_k \|^2} \]
Étant donné que nous connaissons la famille de polynômes avec laquelle nous travaillons, l’objectif est surtout de déterminer les produits scalaires qui permettent d’obtenir nos \(\alpha_k \).
Les modules Python par famille
La bibliothèque numpy.polynomial propose des modules dédiés. Chaque famille est définie par son intervalle \(I\) et son poids \(w(t)\) que voici :
Le module Legendre (Intervalle \([-1, 1]\), poids \(1\))
C’est le module le plus utilisé pour l’approximation « classique » (moindres carrés). En ECG, il correspond au produit scalaire classique :
\[ \langle f, g \rangle = \int_{-1}^{1} f(t)g(t)dt \]
Importation : from numpy.polynomial import Legendre
Fonction clé : Legendre.fit(x, y, deg) calcule le meilleur polynôme d’approximation.
Le module Chebyshev (Intervalle \([-1, 1]\), poids \(1/\sqrt{1-t^2}\))
Les polynômes de Tchebychev sont un immense classique de l’approximation numérique, car ils minimisent l’erreur maximale (traduit vulgairement : ils ne font pas de gros écarts aux bords de l’intervalle).
Importation : from numpy.polynomial import Chebyshev
Usage type : T = Chebyshev([0, 0, 1] crée le polynôme \(T_2(x) = 2x^2 – 1\)
Le module Hermite (Intervalle \(]-\infty, +\infty[\), poids \(e^{-t^2}\))
Ces polynômes sont essentiels en ECG dès que l’on manipule la loi normale. Le poids \(e^{-t^2}\) rappelle en effet la densité de la loi \(\mathcal{N}(0, 1/2)\).
Importation : from numpy.polynomial import Hermite
Application : Utile pour calculer des intégrales de type \(\int_{-\infty}^{+\infty} f(t)e^{-t^2} dt\) via la méthode de Gauss-Hermite.
Le module Laguerre (Intervalle \([0, +\infty[\), poids \(e^{-t}\))
Dès qu’un sujet porte sur la loi exponentielle \(\mathcal{E}(1)\), les polynômes de Laguerre ne sont jamais loin.
Importation : from numpy.polynomial import Laguerre
Usage : On s’en sert pour approximer des fonctions définies sur \(\mathbb{R}^+\).
En Python : L = Laguerre.fromroots([1, 2, 3]) crée le polynôme de Laguerre ayant pour racines 1, 2 et 3.
Comme ces notions sont hors programme, il est inutile de retenir par cœur les poids associés à chaque famille de polynômes, puisqu’elles seront sûrement redonnées dans l’énoncé du sujet.
Implémentation et analyse du code
Nous approximons ici la fonction \(f(t) = \sin(\pi t) + 0.5 \cos(5\pi t)\) sur \([-1, 1]\) grâce aux fameux polynômes de Tchebychev. Nous supposerons que toutes les libraires ont été préalablement importées !
On obtient alors le graph suivant :
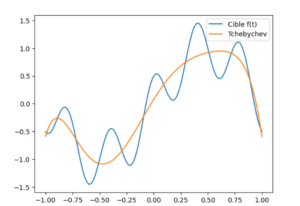
Analysons ligne par ligne le code
- On définit d’abord de manière classique la fonction que l’on cherche à approximer, puis on crée un vecteur de données d’abscisses sur l’intervalle sur lequel nous voulons approximer notre fonction. Attention ici, l’intervalle choisi n’est pas à notre discrétion, il dépend très précisément de la famille des polynômes choisis, dont tu retrouveras les intervalles correspondants dans la deuxième partie de cet article.
- On produit ensuite un vecteur constitué des images de la fonction que l’on cherche à approximer à partir du vecteur d’abscisses que l’on possède.
- Il est ensuite primordial de choisir le degré des polynômes pour pouvoir ensuite définir la fonction polynomiale qui va permettre d’approximer notre fonction initiale. C’est cette ligne qui est au cœur de tout cet article, car elle permet à elle seule de produire le polynôme souhaité.
- Enfin, rien de plus simple, on affiche notre fonction initiale et notre polynôme !
L’avantage de polynom.fit( X,Y,deg) est que la syntaxe est universelle. Si tu sais utiliser cette fonction avec les polynômes de Tchebychev comme nous l’avons fait ici, tu sais utiliser les autres familles grâce à des méthodes communes en remplaçant Chebyshev (attention à la syntaxe anglaise du nom) par Laguerre, Hermite ou encore Legendre.
Conclusion
En définitive, il est très aisé de réaliser une approximation polynomiale à l’aide de ces familles de fonctions et cela pourrait largement faire l’objet d’une question d’un sujet d’écrit dans lequel la fonction polynom.fit serait expliquée, puisque cette dernière est bien entendue hors programme. Il est toutefois de bon goût de maîtriser l’architecture de ce script pour être à l’aise si une telle question venait à tomber au concours !
Tu peux retrouver ici le méga-répertoire qui contient toutes les annales de concours et les corrigés. Tu peux également accéder ici à toutes nos autres ressources mathématiques !



