





Dans cet article, nous allons aborder un chapitre difficile du programme de deuxième année où nous allons explorer l’optimisation des fonctions. Notre objectif sera de trouver le minimum d’une fonction grâce à un algorithme Python. Cet article explore le cadre privilégié de la convexité où les minima locaux ont l’élégance d’être globaux, ce qui nous simplifie les affaires, comme nous allons le voir par la suite. Nous allons donc comprendre comment Python nous permet de résoudre ces problèmes avec une efficacité redoutable. Nous débuterons notre propos par quelques rappels sur la notion de convexité et de minimum local et global, avant de définir un algorithme direct pour déterminer un minimum, puis nous développerons plus longuement notre propos sur un algorithme « itératif ».
Préambule : Nous nous concentrerons ici sur la recherche du minimum global. S’agissant de la recherche d’un maximum global d’une fonction \(f\), il conviendra simplement d’étudier le minimum de \(-f\).
Introduction et rappels mathématiques
Ensemble et fonction convexe
En optimisation, lorsque l’on cherche le minimum global d’une fonction, le plus grand danger est de rester piégé dans un minimum local : l’algorithme croit avoir trouvé le point le plus bas, car tout mouvement autour de lui fait remonter la fonction, alors qu’un minimum bien plus profond existe ailleurs.
Face à ce problème, la convexité change tout. Si une fonction est convexe sur un ensemble convexe, alors on peut prouver :
-
que tout minimum local est un minimum global ;
-
qu’en cas de convexité stricte, ce minimum global est unique.
En d’autres termes, la stricte convexité est parfaite pour un algorithme cherchant un minimum global, puisqu’il ne risque pas de trouver un minimum local qu’il considérerait comme global. C’est pour cela que nous allons nous concentrer sur les fonctions strictement convexes.
Définition générale de la convexité
Pour rappel, un ensemble \( C \subset \mathbb{R}^n \) est dit convexe si pour tout \( (x, y) \in C^2 \) et tout \( \lambda \in [0, 1] \), le segment \( [x, y] \) est inclus dans \( C \), ce qui se traduit par :
\[ \forall (x, y) \in C^2, \forall \lambda \in [0, 1], \quad \lambda x + (1-\lambda)y \in C \]
Caractérisation par les dérivées
Ordre 1 : Si \( f \) est de classe \( \mathcal{C}^1 \), \( f \) est convexe si et seulement si sa courbe est toujours située au-dessus de ses tangentes :
\[ \forall (x, y) \in C^2, \quad f(y) \ge f(x) + \langle \nabla f(x), y-x \rangle \]
Ordre 2 : Si \( f \) est de classe \( \mathcal{C}^2 \), \( f \) est convexe si et seulement si sa matrice hessienne \( \nabla^2 f(x) \) est symétrique positive en tout point \( x \) de \( C \).
On peut alors prouver le point suivant, au programme en deuxième année, (nous admettrons sa démonstration) :
Soit \( f \) une fonction convexe de classe \( \mathcal{C}^1 \) sur un ouvert \( C \). Un point \( x^* \in C \) est un minimum global de \( f \) si et seulement si \( \nabla f(x^*) = 0 \).
Nous reviendrons sur cette caractérisation du minimum global, puisque c’est lui qui nous servira à mettre en place l’algorithme itératif. Mais pour l’instant, voyons le cas le plus simple, à savoir l’algorithme direct disponible dans la bibliothèque SciPy.
Mise en œuvre avec Python : la bibliothèque SciPy
Ce premier algorithme repose sur la bibliothèque SciPy, ce qui fait que le code sera relativement court, mais opaque sur son fonctionnement.
L’outil universel : scipy.optimize.minimize
Ajouter des contraintes
Cet algorithme fonctionne également lorsque l’on travaille en optimisation sous contrainte (la contrainte linéaire étant au programme en ECG). Supposons qu’on impose \(x_0 + x_1 = 10\).
Ici, le ‘eq’ signifie que l’on travaille avec une contrainte d’équation (et non d’inéquation, auquel cas on utiliserait ‘ineq’). ‘fun’ sert ensuite à définir la fonction. Attention toutefois, parce que la contrainte doit être écrite sous la forme \(g(x_0;x_1) = 0\)
Si cet algorithme est simple d’utilisation et direct, il ne montre pas comment il fonctionne et est de ce fait peu utile pour un sujet de concours cherchant à évaluer la compréhension des étudiants. C’est pourquoi nous allons désormais développer un algorithme itératif, que nous allons pleinement construire sans recourir à une fonction précodée d’une librairie de Python.
Algorithme itératif : la descente de gradient
Intuition de l’algorithme
L’idée : partir d’un point \(x_k\) choisi au hasard (au moins sur l’ensemble de définition de la fonction tout de même) et se déplacer dans la direction opposée au gradient. En effet, puisque le gradient indique la direction de la pente la plus forte, si l’on se déplace dans la direction opposée, on va en direction d’un minimum.
Graphiquement, cela se comprend assez bien. Prenons par exemple le graph suivant :
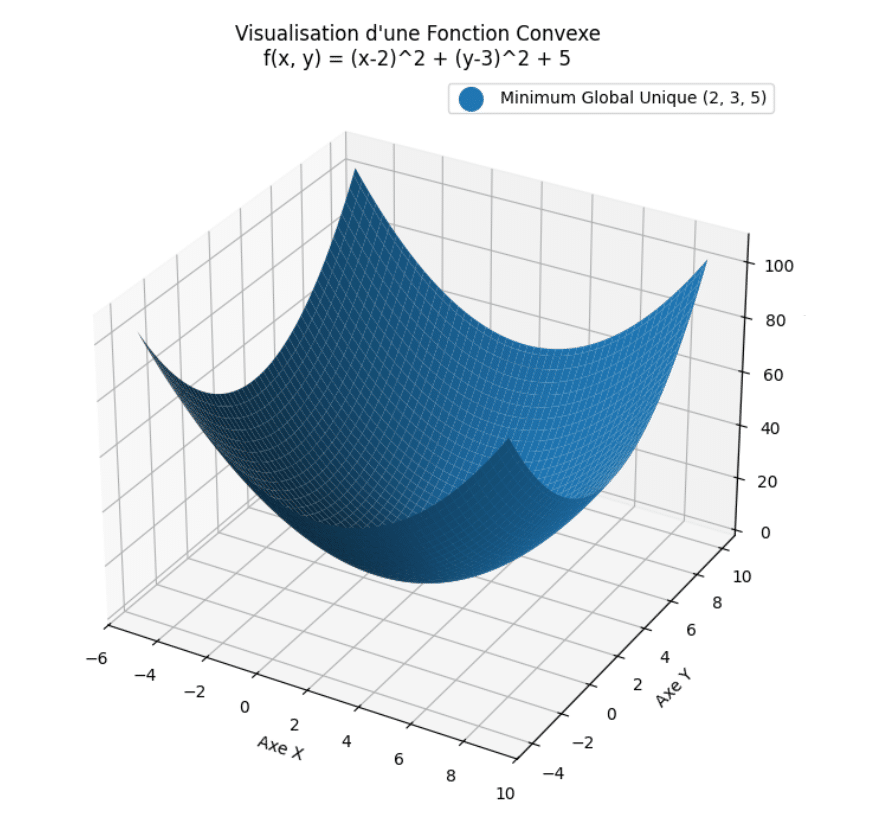
Ici, on a bien une fonction convexe et, si l’on part d’un point « au hasard », que l’on suit la direction inverse du gradient, on finit par tomber sur le minimum global de la fonction.
Voici des lignes de niveau associées à cette fonction, les points bleus représentant les points qui vont progressivement vers le minimum global de la fonction (ici le point pris au hasard pour débuter est situé en \((-4;-3)\) :
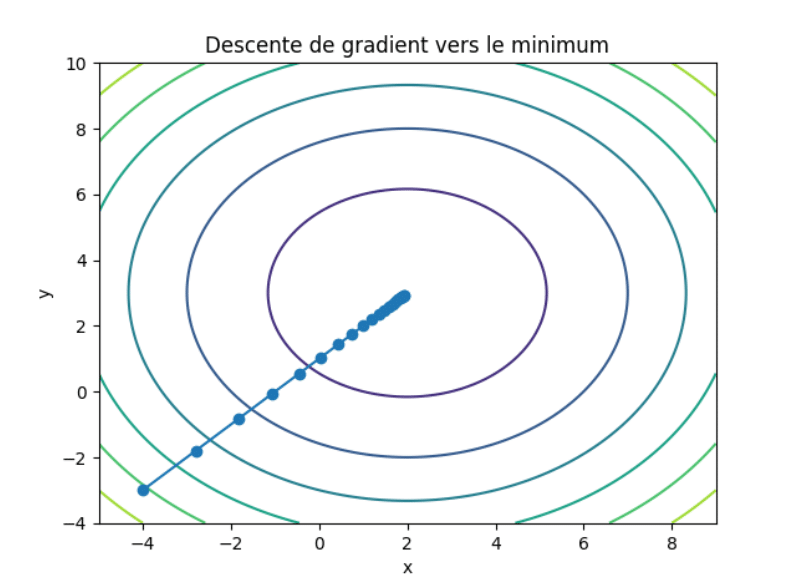
Comment donc construire cette suite ?
Il nous faut une suite qui aille dans la direction inverse du gradient, qu’importe son terme initial comme nous l’avons intuité plus haut.
Définissons donc la suite \((x_k)\) tel que \(\forall k \in \mathbb{N}\) :
Exemple illustratif : la fonction convexe et son minimum global
Nous allons représenter la fonction \(f(x,y) = (x-2)^2 + (y-3)^2 +5\), dont le minimum global est évidemment en \((2;3)\) et vaut \(5\). Si tu veux voir l’allure de la fonction, tu pourras regarder le graph juste au-dessus qui représente précisément cette fonction.
Avant de poursuivre avec le script, je te conseille de revoir les fonctions utilisées pour afficher des fonctions à plusieurs variables en Python puisque nous n’allons pas revenir sur l’explication de toutes ces fonctions ci-dessous, afin de nous concentrer sur l’explication du fonctionnement du code. Pas de panique, le code est assez long, mais se segmente assez bien et peut être compris aisément si l’on maîtrise chacun des éléments qu’il convoque.
Explication
On crée la fonction dont on cherche le minimum, on définit son gradient, puis le pas \(\alpha\) et le nombre d’itérations (de points progressifs, cf. la sortie du script ci-dessous). Ensuite, on crée le point de départ et des listes qui vont respectivement contenir les abscisses et les ordonnées des différents points progressifs qui vont se rapprocher vers le minimum global de la fonction.
On crée ensuite une boucle qui va nous permettre de calculer nos nouveaux points. Pour cela, on calcule d’abord le gradient local, puis on se sert de la formule de définition des nouveaux points, comme vu précédemment pour calculer le nouveau point. On ajoute l’abscisse et l’ordonnée de ce nouveau point aux deux vecteurs \([x]\) et \([y]\).
Ceci étant fait, il n’y a plus rien de spécifique à notre algorithme, on définit la grille en 2D, on crée la fonction dans l’espace et nous précisons l’image de sortie en affichant les axes et en lui inscrivant un titre (optionnel).
On obtient alors un graphe de ce type (que nous avons croisé plus haut) :

Dans cette situation, en pratique, on demande à la fonction de nous retourner le point constitué de la dernière valeur de \(x\) et de \(y\) (ici on obtiendrait \((2;3)\)).
Le piège de la non-convexité
Pour bien faire comprendre pourquoi on préfère la convexité, il faut montrer le contre-exemple. Ce graphique représente une fonction non convexe classique qui fait intervenir des fonctions trigonométriques, créant ainsi des minima locaux multiples.
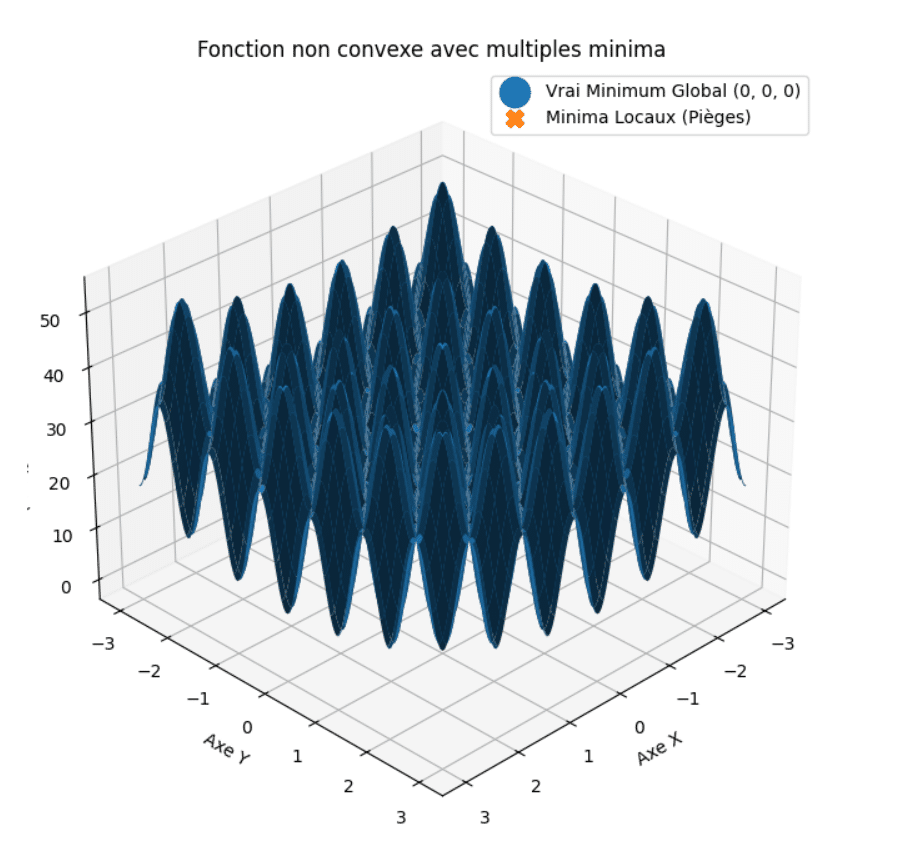
Le problème ici est que si l’on part d’un point au hasard \(x_0\), l’algorithme va renvoyer un minimum local (on sera effectivement dans un creux), mais rien ne nous prouve que ce minimum local est global.
Conclusion
En définitive, le minimum global d’une fonction peut être trouvé algorithmiquement en Python en passant par un algorithme direct ou itératif. L’algorithme direct est plus rapide, mais peu susceptible de tomber le jour J, puisqu’il ne repose sur aucune compétence algorithmique du candidat. En revanche, maîtriser l’algorithme itératif montre que l’étudiant maîtrise tant l’aspect mathématique pure que le codage Python.
Tu peux également retrouver ici le méga-répertoire qui contient toutes les annales de concours et les corrigés. Tu peux aussi accéder ici à toutes nos autres ressources mathématiques !



